csvbase is a simple website for sharing table data. Join the discord.
Being on The Semantic Web is easy, and, frankly, well worth the bother
Web 3.0 was not about the blockchain, thank god
2024-08-20
by Cal Paterson
The Semantic Web is the old Web 3.0. Before "Web 3.0" meant crypto-whatnot, it meant "machine-readable websites".
I thought this concept hadn't really gone anywhere but it turns out that The Semantic Web (best read in a very deep voice) is now very widely adopted.
The Semantic Web is so widely adopted in fact that I think it's fair to say that we're already on Web 3.0. It's not the future, it's the present. I suppose that means the blockchain crowd will need to argue their case to get all that crypto stuff into the next major version. Good luck to them, really.
If Web 3.0 is already here, where is it, then? Mostly, it's hidden in the markup.
JSON-LD for a BlogPosting
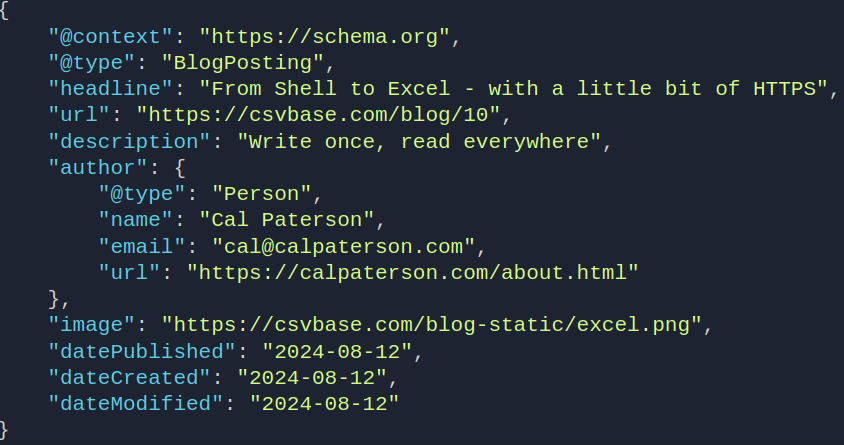
A worked example might help. Here's how Semantic Web metadata is added for a blog post, for example the one you're reading now.
You include a special <script type="application/ld+json"> element inside the
<head> of an HTML page. Inside that element is some
JSON-LD.
JSON-LD (JSON "for Linked Data") is the leading format for encoding Sematic Web
metadata. It's just JSON, really. There are schemas that lay out the
"types" you can use to describe the stuff on your page. For a blog post, the
right type is BlogPosting. Here's a (mildly
truncated) example of a BlogPosting:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "From Shell to Excel - with a little bit of HTTPS",
"url": "https://csvbase.com/blog/10",
"description": "Write once, read everywhere",
"author": {
"@type": "Person",
"name": "Cal Paterson",
"email": "cal@calpaterson.com",
"url": "https://calpaterson.com/about.html"
},
"image": "https://csvbase.com/blog-static/excel.png",
"datePublished": "2024-08-12",
"dateCreated": "2024-08-12",
"dateModified": "2024-08-12"
}
It's all pretty self expanatory:
-
keys starting with
@are metadata (meta-metadata?)@contextis the namespace. Usually it's schema.org@typeis the class,BlogPosting
- the other keys are just things allowed in the
BlogPostingtype - the values of keys can be other types, eg
Personfor theauthorkey in this case
What's in it for me?
Does anyone actually read all that stuff? Yes, a lot of bots are out there parsing JSON-LD metadata. Nice things tend to happen to blog posts that include the Semantic Web metadata:
Social media sites (Twitter/Discord/Facebook/WhatsApp/etc) start showing that nice link preview with an image for your links. Link previews usually look a bit like this:
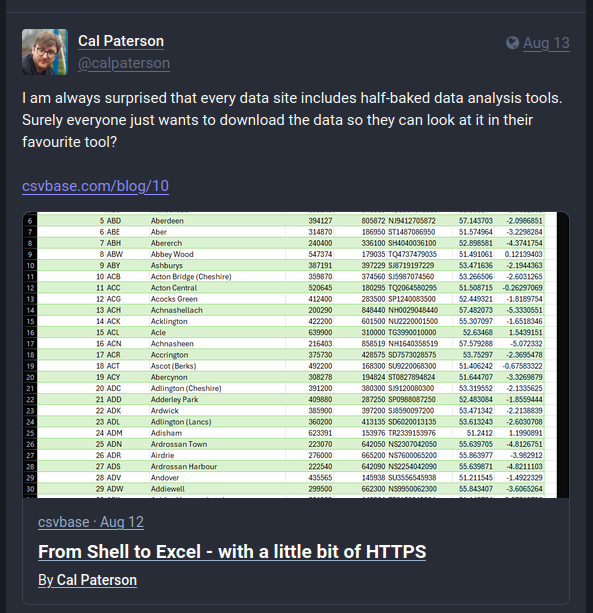
People do click on these link previews more often than on "bare urls", which is something that drives adoption of the Semantic Web.
Search engine web crawlers also make use of this metadata both to crawl a bit more intelligently but also to show more information in search results (for example: who the author is). Again, people are more likely to click on such "enhanced" search results, which is another thing that has driven adoption.
Automated link aggregators show your post to their users. I once woke to many many nice emails from people who normally wouldn't have read my blog. After being initially puzzled I eventually learned that Android had decided, all on its own, to show my blog post on its on-phone news screen. All possible because of Semantic Web metadata.
Many other, usually nice, things can happen. The joy of The Semantic Web is that it is permissionless as well as "vendor-neutral". Anyone can take the metadata and run with it. That's cool, that's the web spirit.
Is it really hard?
Not really, no. A bit of JSON, containing things already on the page anyway, just laid out in a way for computers to read. If people can write enormous frontend apps I think they can figure out JSON-LD.
JSON-LD for other stuff
There are other JSON-LD "types" than just BlogPosting. A lot more. Some
well supported ones:
csvbase is a website full of table data
(tinder-for-dogs style pitch: "Github, for data tables"), so it uses the
Dataset type to describe each of tables
(for example) in a
machine-readable way. Here's an example of the JSON-LD csvbase includes on
each table page:
{
"@context": [
"https://schema.org",
{
"csvw": "https://www.w3.org/ns/csvw#"
}
],
"@type": "Dataset",
"name": "stock-exchanges",
"url": "https://csvbase.com/meripaterson/stock-exchanges",
"isAccessibleForFree": true,
"distribution": [
{
"@type": "DataDownload",
"contentUrl": "https://csvbase.com/meripaterson/stock-exchanges.csv",
"encodingFormat": "text/csv",
"contentSize": "16222"
},
{
"@type": "DataDownload",
"contentUrl": "https://csvbase.com/meripaterson/stock-exchanges.parquet",
"encodingFormat": "application/parquet",
"contentSize": "10751"
},
{
"@type": "DataDownload",
"contentUrl": "https://csvbase.com/meripaterson/stock-exchanges.xlsx",
"encodingFormat": "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
"contentSize": "15500"
},
{
"@type": "DataDownload",
"contentUrl": "https://csvbase.com/meripaterson/stock-exchanges.jsonl",
"encodingFormat": "application/x-jsonlines",
"contentSize": "38627"
}
],
"dateCreated": "2022-04-25T13:43:24.746075+01:00",
"dateModified": "2023-04-02T20:27:33.255648+01:00",
"maintainer": {
"@type": "Person",
"name": "meripaterson",
"url": "https://csvbase.com/meripaterson"
},
"description": "The world's stock exchanges...",
"mainEntity": {
"@type": "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "csvbase_row_id",
"csvw:datatype": "integer"
},
{
"csvw:name": "Continent",
"csvw:datatype": "string"
},
{
"csvw:name": "Country",
"csvw:datatype": "string"
},
{
"csvw:name": "Name",
"csvw:datatype": "string"
},
{
"csvw:name": "MIC",
"csvw:datatype": "string"
},
{
"csvw:name": "Last changed",
"csvw:datatype": "date"
}
]
}
}
}
There's a lot of stuff in there. From basic things like the last time the data was changed (personal bugbear of mine) to some more complicated stuff.
Several DataDownload objects are included, to help bots understand where
people can go to just download the data, without having the visit the site.
Hopefully that's nice for people viewing tables through data-specific search
engines, like Google's Dataset
Search. Save them a click.
There's also some more advanced stuff. The JSON-LD document actually includes
two schemas. One is the ordinary "schema.org" one (Dataset) but the other
is a schema called "CSV on the
Web", which allows you to describe
the columns and the types of those columns --- as well as other more detailed
data I haven't sorted out yet.
I haven't direct evidence that anyone is yet doing much with these CSVW types yet but Google do document that they read it so perhaps there is more to come on this in the future from them. And of course, there is nothing to stop anyone else using it. It's all standardised stuff.
It is really necessary? "Doesn't AI solve this?"
It would of course be possible to sic Chatty-Jeeps on the raw markup and have it extract all of this stuff automatically. But there are some good reasons why not.
The first is that large language models (LLMs) routinely get stuff wrong. If you want bots to get it right, provide the metadata to ensure that they do.
The second is that requiring an LLM to read the web is thoroughly disproportionate and exclusionary. Everyone parsing the web would need to be paying for pricy GPU time to parse out the meaning of the web. It would feel bizarre if "technological progress" meant that fat GPUs were required for computers to read web pages.
Alternatives
JSON-LD is not the only form of Semantic Web metadata, though it's increasingly got the most momentum. There is some overlap between the various schemes and many bots will parse whatever they can find. Here's a quick overview of the alternatives:
At some point Facebook created the Open Graph Protocol, a
standard based on using special <meta> tags. It's widely used and supported
but only covers the kinds of things you might post to Facebook: articles,
songs, videos, etc. What zoomers call "Content".
There is also "microdata". It's very simple but I think quite hard to parse out. Bits of it are well supported.
Twitter published a spec for "Twitter Cards" which pretty much just lets you describe how you want your thing to appear on Twitter. It's pretty limited - but Twitter is popular - so this is widely implemented.
Before JSON-LD there was a nest of other, more XMLy, standards emitted by the various web steering groups. These actually have very, very deep support in many places (for example in library and archival systems) but on the open web they are not a goer.
Boring technology
It is surprising how low-key The Semantic Web is. Thousands of sites are already setting this metadata. The Semantic Web is already widespread, it's just that there was no moment of victory.
If you think csvbase is cool:
- become a supporter
- star the github repo
- follow me on mastodon
- write me an email
Notes
Googlers, if you're reading this, JSON-LD could have the same level of public awareness as RSS if only you could release, and then shut down, some kind of app or service in this area. Please, for the good of the web: consider it.
Semantic Web information on websites is a bit of a "living document". You tend publish something, then have a look to see what people have parsed (or failed to parse) it and then you try to improve it a bit. If you have ideas for ways that csvbase can improve its metadata, please open an issue on the github repo.