csvbase is a simple website for sharing table data. Join the discord.
How does it know I want csv? — An HTTP trick

Forgotten parts of RFC2616
2023-01-17
by Cal Paterson
How come when you visit https://csvbase.com/meripaterson/stock-exchanges in a browser you get a webpage –:
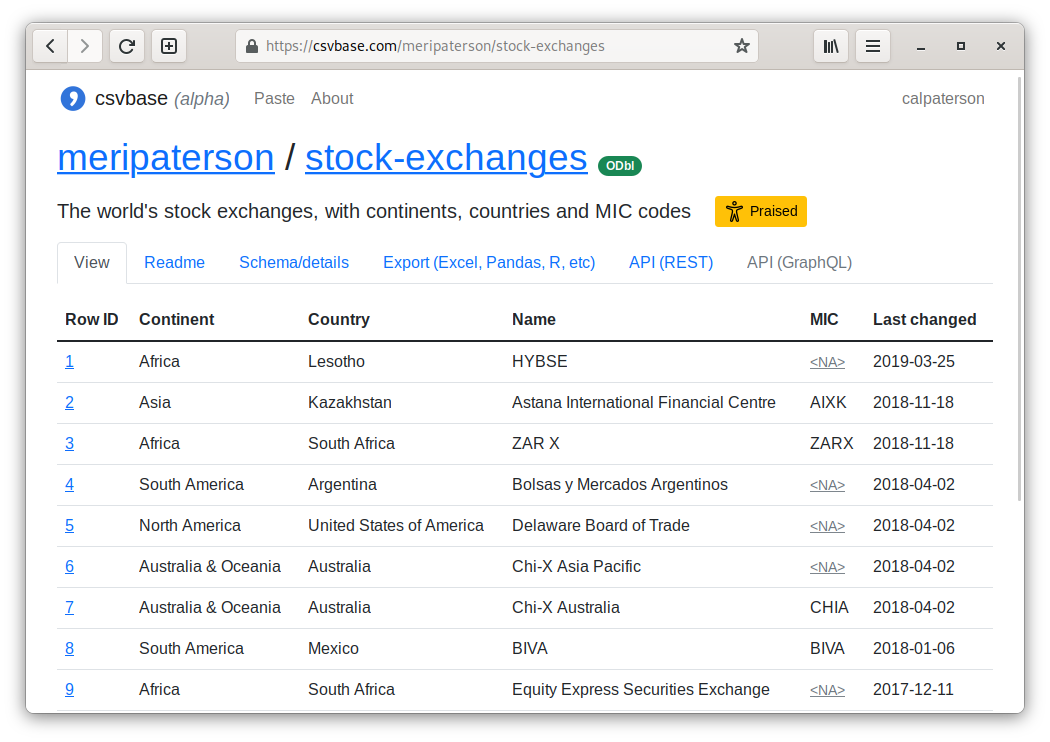
but when you curl the same url you get a csv file?:
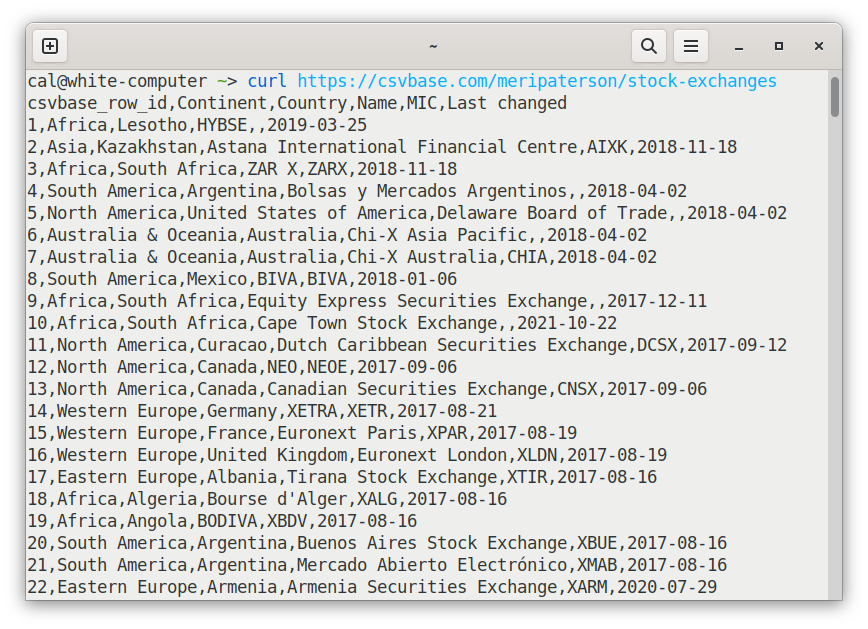
The url is the same - so how come?
The answer is HTTP's built-in "content negotiation".
How content negotiation works
When an HTTP client sends any request, it sends "headers" with that request. Here are the headers that Google Chrome sends:
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding: gzip, deflate, br
accept-language: en-GB,en-US;q=0.9,en;q=0.8
cache-control: no-cache
pragma: no-cache
sec-ch-ua: "Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Linux"
sec-fetch-dest: document
sec-fetch-mode: navigate
sec-fetch-site: none
sec-fetch-user: ?1
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
That's a lot. Only the first of these is relevant: the accept header:
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
The accept header is an unordered list of preferences for what media type
(aka "Content Type", or file format) the server should send.
Chrome is saying:
-
Ideally, give me:
text/html(ie: HTML)application/xhtml+xml(XHTML)image/avifimage/webp- or
image/apng(a animated version of a PNG)
-
Otherwise ("q", or quality, 0.9), give me
application/xml- or
application/signed-exchange;v=b3
-
And if none of these are available (lowest priority; q=0.8):
- just send me anything (
*/*)
- just send me anything (
csvbase has an HTML representation of the url being requested, which is Chrome's joint top preference, so it just replies with that.
What accept header does curl send? It sends just:
accept: */*
Much shorter. Curl will take anything. And csvbase has a default format: csv, so it replies with that.
"Why though?", escape hatches and non-negotiables
The main reason why csvbase bothers at all with this is to make it easier to
export tables. For example, to get a table loaded into
pandas, all you have to do
is paste the url into the first argument for pandas' read_csv - the same url
as for the page:
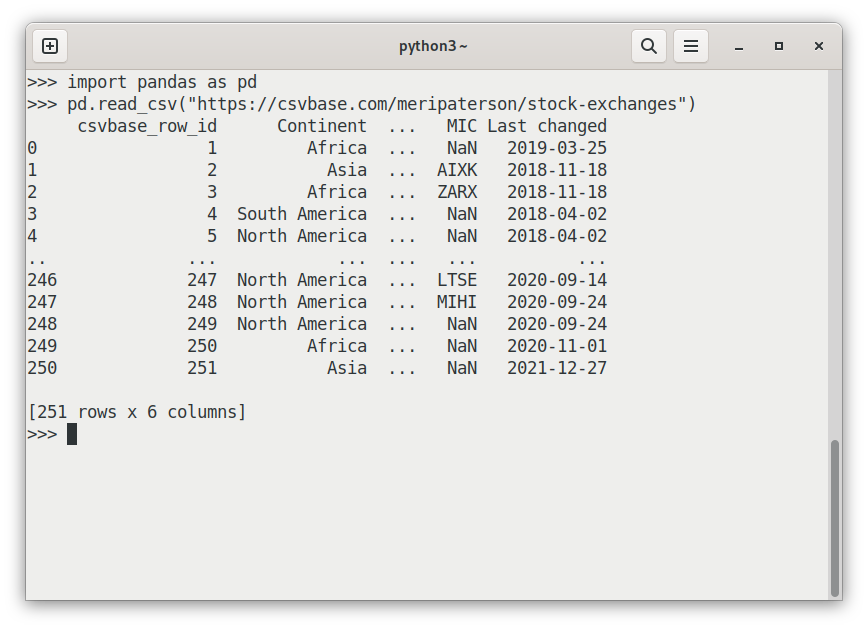
This works in most tools - curl, pandas, R and many others. But not all. Some, like Apache Spark, ask for HTML for some reason. So csvbase has an escape hatch from content negotiation — adding a file extension:
https://csvbase.com/meripaterson/stock-exchanges.csv always returns csv file.
This escape hatch is also useful for other formats. Media types are controlled by the Internet Assigned Numbers Authority. Not every file format has been given a media type. For example, parquet (the current favourite of most data scientists) doesn't have a media type. Neither does jsonlines. At least not yet.
csvbase can output in those formats too, but there's no way to content neogiate them - at least not until the IANA get around to officially assigning them a media type.
Until then, use: https://csvbase.com/meripaterson/stock-exchanges.parquet
You can even do:
import pandas as pd
pd.read_parquet("https://csvbase.com/meripaterson/stock-exchanges.parquet")