csvbase is a simple website for sharing table data. Join the discord.
Parquet: more than just "Turbo CSV"

Quicker, but also more convenient
2023-04-03
by Cal Paterson
Parquet is an efficient, binary file format for table data. Compared to csv, it is:
- Quicker to read
- Quicker to write
- Smaller
On a real world 10 million row financial data table I just tested with pandas I found that Parquet is about 7.5 times quicker to read than csv, ~10 times quicker to write and a about a fifth of the size on disk. So way to think of Parquet is as "turbo csv" - like csv, just faster (and smaller).
That's not all there is to Parquet though. Although Parquet was originally designed for Big Data, it also has benefits for small data.
Scaling down
One of the main advantages of Parquet is the format has an explicit schema that is embedded within the file - and that schema includes type information.
So unlike with csv, readers don't need to infer the types of the columns by scanning the data itself. Inferring types via scanning is fragile and a common source of data bugs. It's not uncommon for the values for a column to begin looking like ints only for later in the file to change into freeform text strings. When exchanging data, it's better to be explicit.
The representation of types is also standardised - there is only one way to
represent a boolean - unlike the YES, y, TRUE, 1, [x] and so on of
csv files - which all need to be recognised and handled on a per feed basis.
Date/time string parsing is also eliminated: Parquet has both a date type and
the datetime type (both sensibly recorded as integers in UTC).
Parquet also does away with character encoding confusion - a huge practical problem with textual file formats like csv. Early on, God cursed humanity with multiple languages. The early programmers cursed computers too: there are numerous ways to represent characters as bytes. Different tools use different encodings - UTF-8, UTF-16, UTF-16 with the bytes the wrong way round, Win-1252, ASCII (but something else on days when the feed needs to include a non-ASCII character) - the list goes on.
More sophisticated programs apply statistics to the byte patterns in the early parts of the file to try to guess what the character encoding might be - but again, it's fragile. And if you guess wrong - the result is garbled nonsense.
And finally, Parquet provides a single way to represent missing data - the
null type. It's easy to tell "null" apart from "", for
example. And the fact that there is an official way to represent null (mostly)
eliminates the need to infer that certain special strings (eg N/A) actually
mean null.
Column — and row — oriented
How does Parquet work then? Parquet is partly row oriented and partly column oriented. The data going into a Parquet file is broken up into "row chunks" - largeish sets of rows. Inside a row chunk each column is stored separately in a "column chunk" - this best facilitates all the tricks to make the data smaller. Compression works better when similar data is adjacent. Run-length encoding is possible. So is delta encoding.
Here's a diagram:

At the end of the file is the index, which contains references to all the other row chunks, column chunks, etc.
That's actually one of the few downsides of Parquet - because the index is at the end of the file you can't stream it. A lot of programs that process csv files stream through them to allow them to handle csv files that are larger than memory. Not possible with Parquet.
Instead, with Parquet, you tend to split your data across multiple files (there is explicit support for this in the format) and then use the indexes to skip around to find the data you want. But again - that requires random access - no streaming.
Trying it out
You can add .parquet to any csvbase table url to get a Parquet file, so
that's an easy way to try the format out:
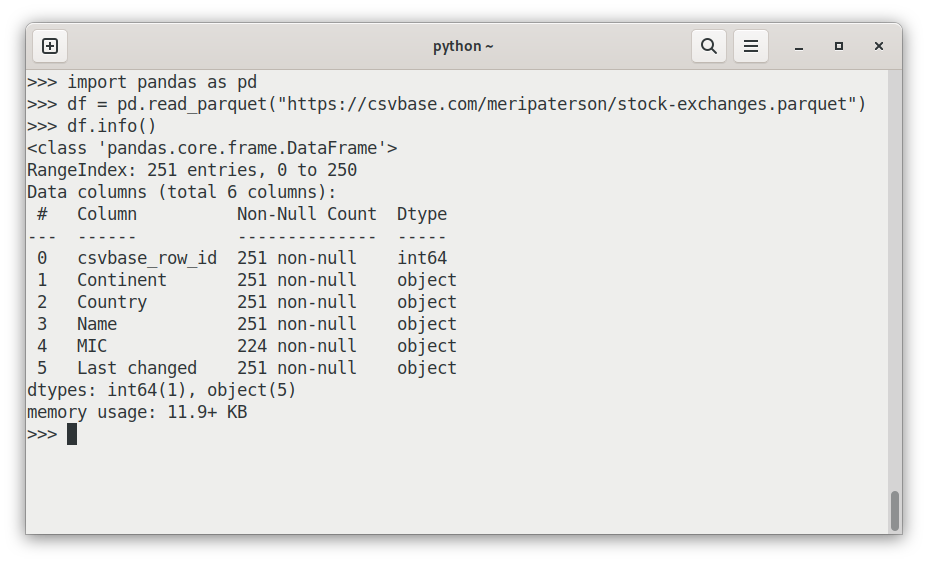
import pandas as pd
df = pd.read_parquet("https://csvbase.com/meripaterson/stock-exchanges.parquet")
If you want to see the gory details of the format, try the parquet-tools
package on PyPI with a sample file:
pip install -U parquet-tools
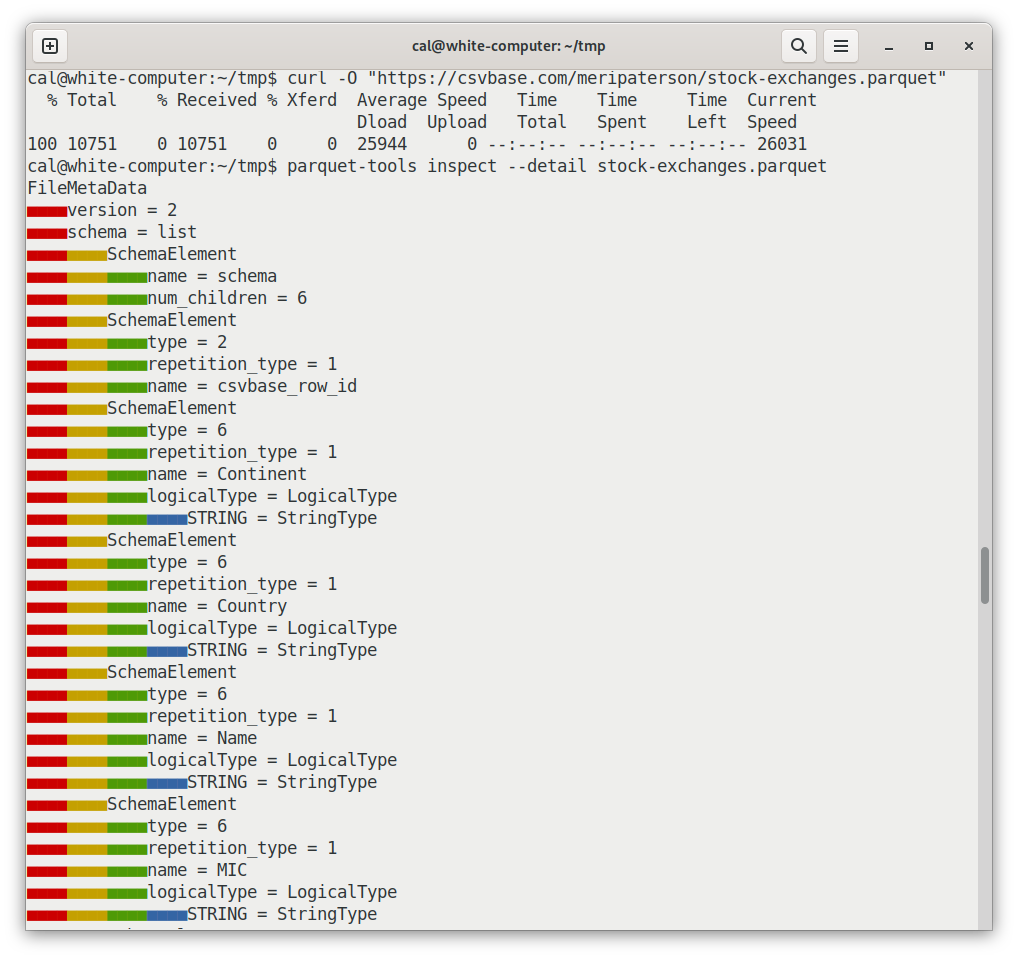
curl -O "https://csvbase.com/meripaterson/stock-exchanges.parquet"
parquet-tools inspect --detail stock-exchanges.parquet
That shows a lot of detail and in conjunction with the spec can help you understand exactly how the format is arranged.
Keep in touch
Please do send me an email about this article, especially if you disagreed with it.
I am also on Mastodon: @calpaterson@fosstodon.org.
If you liked this, you might like other things I've written: on the csvbase blog, or on my blog.
Follow new posts via RSS.