csvbase is a simple website for sharing table data. Join the discord.
Client libraries are better when they have no API
fsspec is secretly everywhere, and boss
2024-04-10
by Cal Paterson
When I met a friend in a pub recently and I told him I was writing a client library for csvbase, he did laugh a bit. "Can't people just use curl?"
It's true. On csvbase, you can just curl any table url and get a csv file. Through the magic of HTTP, this web-page:
becomes this csv file inside curl:
[For details of how that trick works, see an older blog post]
That barely qualifies as an API, it's just HTTP. So what possible use could a client library be?
And of course client libraries add mental overhead of their own. You have to read some docs, learn some methods and then and the end you still have to add some code to use whatever library it is.
Wouldn't you rather just not?
I would certainly rather not. With that in mind, I've written a client library that has no API.
No API
Wait, no API?:
>>> import pandas as pd
>>> df = pd.read_csv("csvbase://calpaterson/onion-vox-pops")
>>> df.quote[0]
"""I realize passengers are concerned, but speaking as a pilot,
there's no better place to drop acid than 40,000 feet in the air."""
(A man after my own heart.)
But yes, no API. I resent writing data APIs anyway (that's why I wrote
csvbase - to do it once, generically). So if you want, just pull dataframes
down from csvbase with Pandas itself. pip install
csvbase-client and Pandas will
suddenly learn the csvbase:// url scheme.
And what if you want to write a dataframe to csvbase? Is there an API for
that? Again: no. You call the usual method: DataFrame.to_csv:
>>> import string # from the stdlib
>>> alphabet_df = pd.DataFrame(enumerate(string.ascii_lowercase, start=1),\
columns=("number", "letter")).set_index("number")
>>> alphabet_df.to_csv("csvbase://calpaterson/alphabet")
You do admittedly need to put your csvbase username and API key into
~/.netrc first. Here's mine:
machine csvbase.com
login calpaterson
password hunter42
You can check up on calpaterson/alphabet: it's a real table on
csvbase.com now.
But perhaps you don't like Pandas. You prefer Polars, that other dataframe library. Again: I refuse to write an API. You can just use Polars itself:
>>> import polars as pl
>>> pl.read_csv("csvbase://calpaterson/alphabet")
shape: (26, 3)
┌────────────────┬────────┬────────┐
│ csvbase_row_id ┆ number ┆ letter │
│ --- ┆ --- ┆ --- │
│ i64 ┆ i64 ┆ str │
╞════════════════╪════════╪════════╡
│ 1 ┆ 1 ┆ a │
│ 2 ┆ 2 ┆ b │
│ 3 ┆ 3 ┆ c │
│ 4 ┆ 4 ┆ d │
│ 5 ┆ 5 ┆ e │
│ … ┆ … ┆ … │
│ 22 ┆ 22 ┆ v │
│ 23 ┆ 23 ┆ w │
│ 24 ┆ 24 ┆ x │
│ 25 ┆ 25 ┆ y │
│ 26 ┆ 26 ┆ z │
└────────────────┴────────┴────────┘
What about Dask? Same thing:
>>> import dask.dataframe as dd
>>> dd.read_csv("csvbase://calpaterson/alphabet")
Dask DataFrame Structure:
csvbase_row_id number letter
npartitions=1
int64 int64 string
... ... ...
Dask Name: read_csv, 1 expression
Expr=ReadCSV(16ad101)
I imported pandas as pd, I imported polars as pl and I imported
dask.dataframe as dd. But I didn't import csvbase_client. Unnecessary -
there is no API.
Enter fsspec
How is this all working? Have I perpetrated a kind of grand, Jia Tan-style jedi mind trick on the maintainers of these dataframe libraries, secretly sneaking csvbase-specific code into their repos?
I haven't. All of these dataframe libraries (and probably others I haven't thought of) use a standard filesystem interface library, called fsspec. csvbase-client just implements an adaptor for fsspec:
from fsspec.spec import AbstractFileSystem, AbstractBufferedFile
class CSVBaseFileSystem(AbstractFileSystem):
def _open(self, path, mode="rb"):
return CSVBaseFile(self, path, mode)
class CSVBaseFile(AbstractBufferedFile):
def _fetch_range(self, start: int, end: int) -> bytes:
...
fsspec already comes with built-in adaptors for object stores, webdav, Github, Dropbox and lots more. It's a pretty nice abstraction layer. csvbase's client is just one more adaptor.
For whatever reason, fsspec is not that well known. It has less than 800 stars on github. But it is well used: it's downloaded more than 8 million times a day, usually as an automatically installed dependency of other libraries. That actually makes it the 20th most popular Python package - bigger in fact than Pandas.
At any rate, after my classes are written it just takes a short setuptools incantation to wire my classes into place upon package install:
from setuptools import setup
setup(
name="csvbase-client",
..., # [snip]
entry_points={
"fsspec.specs": [
"csvbase=csvbase_client.fsspec.CSVBaseFileSystem",
],
},
)
Or in pyproject.toml:
[project.entry-points."fsspec.specs"]
csvbase = "csvbase_client.fsspec.CSVBaseFileSystem"
With all this working, the csvbase:// url scheme becomes real and you can use
it inside anything which relies on fsspec, which is a surprisingly large number
of things.
How to use fsspec in your own programs
fsspec is pretty nice. It's very useful when you want, for example, to write a cli program that can write both to a file, and then later an S3 object.
Instead of calling the Python built-in open, you call fsspec.open. It is a
mostly drop-in replacement.
import fsspec
with fsspec.open("csvbase://calpaterson/onion-vox-pops") as vox_pops_f:
print(vox_pops_f.read(100))
That's it. It is extremely simple to integrate against.
There isn't just open, either, but touch, rm, cp, mv - the whole
gang. csvbase-client's support doesn't cover all of these yet, but that is
planned.
And there's a cli tool
I can't get out of writing a cli tool for csvbase. There is no way to avoid that - but I did make it a thin veneer over fsspec.
$ csvbase-client table get calpaterson/alphabet
csvbase_row_id,number,letter
1,1,a
2,2,b
3,3,c
[you know the rest]
But other examples are more fun:
$ csvbase-client table get calpaterson/eurofxref-hist | \
grep USD | \
cut -d, -f 2,4 | \
gnuplot -e "set datafile separator ','; set term dumb; \
plot '-' using 1:2 with lines title 'usd'"
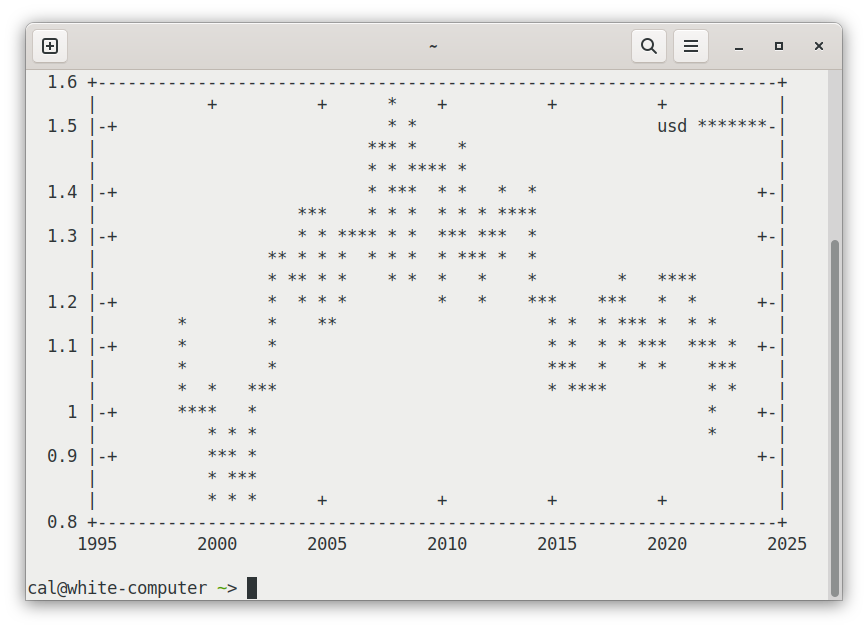
The bytes on the internet are free and you can take them home with you
As with csvbase proper, csvbase-client is open source, so you can just take my code as a starting point and write your own fsspec APIs.
I'm looking forward to expanding on it in future. I'm particularly keen to use fsspec to mount csvbase.com as a filesystem via FUSE. That sounds fun.
Help me out:
- try csvbase-client
-
do me a solid by starring csvbase-client on
github
- star the main project as well if you're feeling extra generous
- regardless, shoot fsspec a github star because they did almost the work
- email me your thoughts
- join the csvbase discord server (this is new)
- or file bugs on github